字节笔记本
2026年5月30日
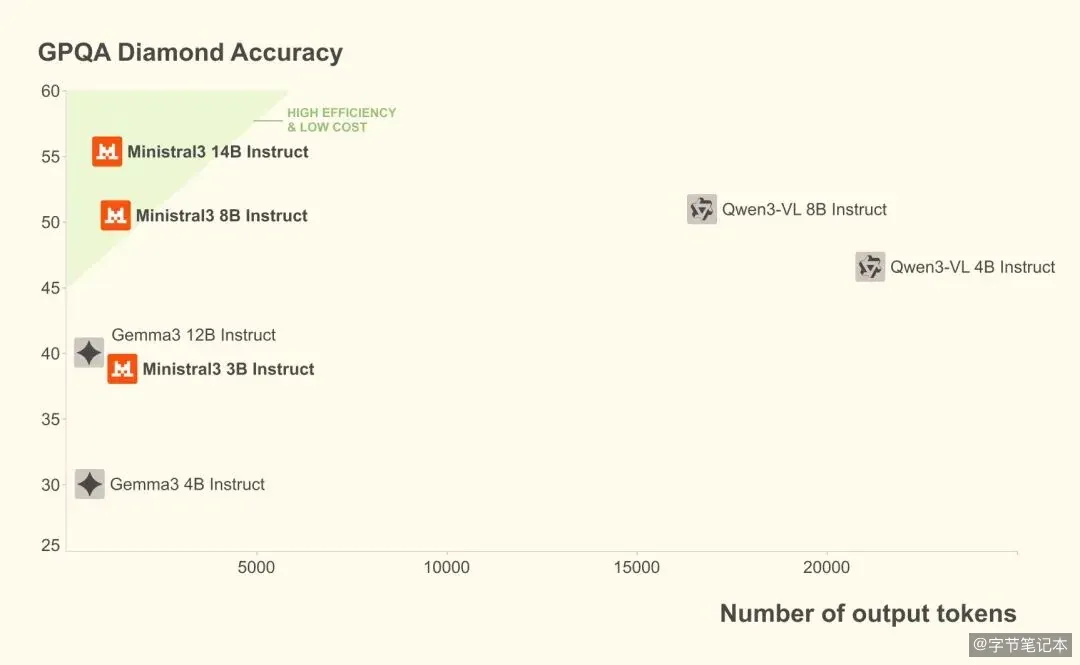
Mistral 3 把 14B 模型做到了 85% GPQA,小模型的天花板又被抬高了
开源大模型领域正在形成一个有趣的趋势:模型不再一味求大,而是开始在"小"上做文章。
Mistral 最新发布的第三代模型,最引人注目的不是那个 675B 参数的稀疏混合专家大模型,而是那个只有 14B 参数的 Ministral 3。
14B 在 GPQA 测试中拿下了 85% 的准确率。这个数字意味着什么?它超过了绝大多数同规模的开源模型,甚至在部分基准上逼近了更大规模的闭源模型。一个能在消费级显卡上运行的模型,做到这个程度,才是真正的实用突破。
Mistral 3 系列包含四个模型:Ministral 14B/8B/3B 三个密集小模型,以及 Mistral Large 3(675B 总参/41B 激活)的 MoE 架构。全部采用 Apache 2.0 许可,这意味着企业可以自由商用。
部署门槛被压到了很低的水平。14B 模型只需 24GB 内存即可本地运行,8B 模型在 16GB 显存的消费级显卡上就能跑。有开发者在 RTX 3090 上实测,14B 推理版本每秒可处理 42 个 token。Ollama 和 vLLM 都已在第一时间提供支持,一行命令即可启动。
真正值得关注的不是参数和跑分本身,而是这背后释放的信号:高质量开源模型的可及性正在快速提升。当 14B 模型能在个人电脑上跑出接近顶尖模型的性能时,AI 应用的部署逻辑会发生变化。不再需要昂贵的云端推理集群,不需要复杂的分布式部署,一个开发者、一台笔记本、一个模型,就能构建生产级的 AI 应用。
Mistral 在模型架构上的选择也值得留意。Large 3 采用的稀疏 MoE 架构,41B 激活参数即可调动 675B 的参数量,这是目前大模型领域效率最高的架构路线之一。而小模型全线支持多模态和 256K 长上下文,说明 Mistral 认为这些能力正在从"高端特性"变成"基础标配"。
模型的门槛在下沉,能力的基线在上升。对于开发者来说,这意味着现在是开始构建 AI 应用最好的时机,不是因为模型最强,而是因为好模型已经足够便宜、足够容易到手。
在 AI 技术快速迭代的今天,保持持续学习的能力比掌握任何特定的技术都更重要。理解底层原理可以帮助你在遇到新技术时更快地上手,可以在不同的技术方案之间做出更明智的选择。建议开发者建立自己的技术框架,而不是追逐每一个新的工具和框架。实践是最好的学习方式,在真实项目中应用新学到的技术,遇到问题并解决,这种经历比任何教程都更有价值。定期整理和复盘也是很好的习惯。将学到的知识归档整理,形成自己的知识库。当需要用到某个技术时,可以直接从自己的知识库中找到相关的参考,而不是从零开始搜索。
技术的价值不在于它有多前沿,而在于它能在多大程度上解决实际问题。AI 技术的快速迭代不是用来追赶的潮流,而是用来解决业务痛点的工具箱。在实际应用中,有时候简单的方案反而最有效。一个 RAG 系统用了最复杂的检索策略但文档处理没做好,效果不如一个文档处理完善但检索策略简单的系统。一个 Agent 系统用了最贵的模型但 prompt 设计粗糙,效果不如一个精心设计 prompt 的普通模型。建议在追求技术先进性之前,先把基础工作做扎实。文档清洗、数据标注、评测体系、监控告警,这些看似基础的工作,往往是决定 AI 项目成败的关键。
在软件开发领域,有一条经验法则:任何在开发阶段看起来很聪明但让调试变得困难的做法,最终都不是好主意。这条法则在 AI 应用开发中尤其适用。AI 应用的不确定性比传统软件高得多,这意味着调试和排查问题的难度也大得多。因此 AI 应用的设计应该追求简单、透明、可追踪。简单意味着每个组件的职责清晰,组件之间的依赖关系明确。透明意味着系统的每个决策过程都可以被追溯和理解。可追踪意味着每次模型调用、每步推理过程都被记录在案。只有做到了这三条,你才能在系统出现问题时快速定位根因。
AI 项目的技术栈选择决定了开发效率和后期维护的成本。Python 是目前 AI 开发的主流语言,拥有最丰富的生态。TypeScript 在 AI 应用开发中也越来越流行,特别是在需要前后端一体化的场景中。选择技术栈时的核心原则是优先考虑团队熟悉的技术,减少学习成本。框架选择同理,LangChain 功能丰富但复杂度也高,直接调用 API 可能更可控。建议从最简单的方案开始,随着需求复杂度的增加逐步引入框架。过早的框架选择会让系统复杂度不必要地增加。