字节笔记本
2026年5月30日
多模态检索不需要三套模型,一个 UniIR 就够了
信息检索领域有一个默认的假设:一个检索模型只在一种场景下工作。文本搜文本,图片搜图片,文本搜图片,各是一套系统。
这在实践中意味着什么?一个电商平台需要维护三套检索模型:用户用文字搜商品、用图片搜同款、用图片加文字描述搜特定款式。每套模型单独训练、单独部署、单独维护。数据和成本都是三倍,还无法共享能力。
UniIR 这篇论文想做的,就是用一个统一的检索模型替代所有这些专用模型。
核心思路很直接:用指令告诉模型"这次你要干什么"。同样的输入,指令不同,检索目标就不同。你输入一张裙子的照片加一句"找类似款式",和输入同一张照片加一句"找红色款",模型能理解这是两种不同的检索意图,返回不同的结果。
听起来简单,但要做到这一点需要解决两个问题。
第一是多模态的对齐。文本、图片、图文对三种模态的数据要在同一个语义空间里可比。UniIR 做了两种融合尝试:评分级融合和特征级融合。前者是各自编码后加权求和,后者是在编码阶段就用跨模态注意力层融合。实验表明,保持预训练模型的原始架构(比如 CLIP 用评分融合、BLIP 用特征融合)效果最好,因为额外添加的随机初始化层在小数据量下容易过拟合。
第二是指令的理解。模型需要从指令中准确推断出检索意图。没有指令的情况下,多任务训练的模型在从异构候选池中检索时,超过 50% 的错误来自模态混淆,搜图片返回了文本,搜文本返回了图片。加入指令微调后,这个错误率降到了 2.7%。
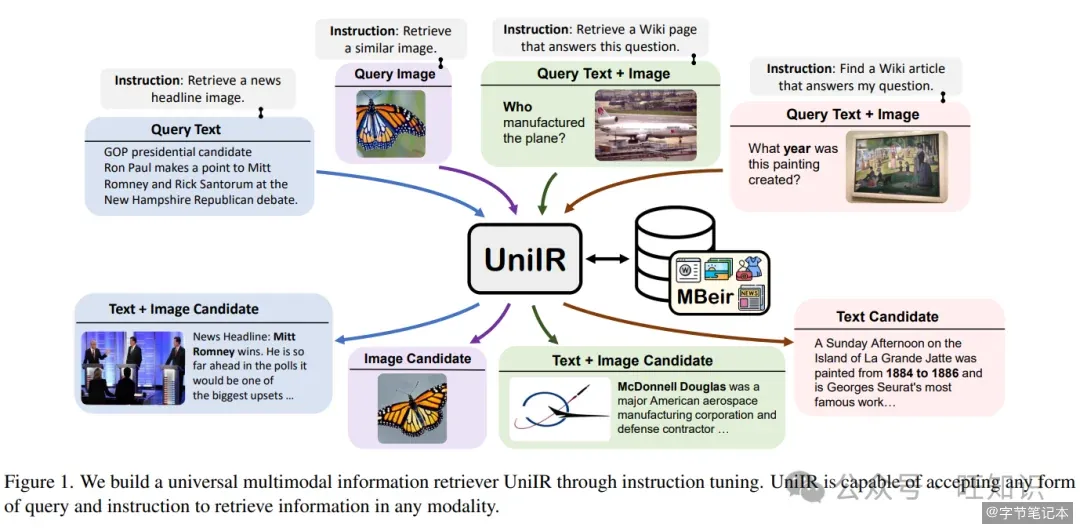
论文基于 10 个数据集构建了 M-BEIR 基准,涵盖 8 种检索任务、150 万查询和 560 万候选池。UniIR 在已有数据集上表现强劲,在未见过的任务上也有零样本泛化能力,这意味着你不需要为每个新场景重新训练模型。
当然,UniIR 离完美还很远。论文自己也承认,现有模型的性能仍然"相对不完美"。对于需要多跳推理的复杂检索场景,统一的指令框架还不够精细。但方向本身是值得关注的:当检索模型从"专才"走向"通才"时,整个信息检索系统的架构成本、维护成本和数据成本都会显著下降。不是每个场景都需要一个专用模型,有时候一个够好的通用模型,比三个完美的专用模型更实用。

大模型的评测是一个多维度的问题。准确率只是评估的一个方面,完整的评测体系还需要包括安全性、可靠性、公平性等多个维度。单一维度的评测容易导致 Goodhart 效应,模型为了在某个指标上取得高分而牺牲其他方面的表现。评测数据的质量和时效性同样重要。评测数据需要定期更新,确保能测试到模型在新领域的能力。评测数据的泄露也是一个严重的问题,如果评测数据出现在训练数据中,评测分数就会虚高。建立一个完善的数据隔离机制,确保训练集和评测集不重叠,是保证评测结果可信的前提。评测体系的建设需要投入持续的资源,但这是值得的。没有好的评测体系,模型优化就失去了方向。
技术的价值不在于它有多前沿,而在于它能在多大程度上解决实际问题。AI 技术的快速迭代不是用来追赶的潮流,而是用来解决业务痛点的工具箱。在实际应用中,有时候简单的方案反而最有效。一个 RAG 系统用了最复杂的检索策略但文档处理没做好,效果不如一个文档处理完善但检索策略简单的系统。一个 Agent 系统用了最贵的模型但 prompt 设计粗糙,效果不如一个精心设计 prompt 的普通模型。建议在追求技术先进性之前,先把基础工作做扎实。文档清洗、数据标注、评测体系、监控告警,这些看似基础的工作,往往是决定 AI 项目成败的关键。