字节笔记本
2026年5月30日
用 GPT 那套提示词套路去调教 DeepSeek R1,反而会适得其反
大多数人对 DeepSeek R1 有一个误解:以为它和 GPT 一样,喂一套结构化提示词就能输出好结果。
实际上恰恰相反。DeepSeek R1 是一个推理模型,它的思考方式和传统大语言模型有本质区别。你给它一套"你是 xxx,你的能力是 xxx,我的要求是 xxx"的模板,反而会限制它的推理能力。DeepSeek 官方论文里明确说了:few-shot 会持续降低模型性能,零样本直接描述问题才是最佳实践。
这意味着什么?意味着过去两年积累的大部分提示词技巧,在 DeepSeek R1 上可能不适用,甚至起反作用。
但这不意味着提示词不重要。只是技巧的方向变了。
对于企业用户来说,真正有效的 DeepSeek 提示词技巧,核心只有一条:把 What 和 How 说清楚。不是用结构化模板约束它,而是用清晰的语境引导它。
比如"如何提高工作效率"这种模糊指令,换成"作为培训经理,需要为全国分公司制定在线营销学习项目,请设计一个每周 3 小时的集中培训规划,确保不同时区都能参与"。差别不在于格式是否结构化,而在于你给的信息量是否足够让模型理解真实场景。
其他几个经过验证的方向同样实用:在指令中加入资源约束("每天只有 2 小时可用")让方案更落地;把复杂需求拆成分步指令让推理更聚焦;提供真实数据而非让模型脑补。这些技巧的共同点不是"怎么写 prompt",而是"怎么描述问题"。
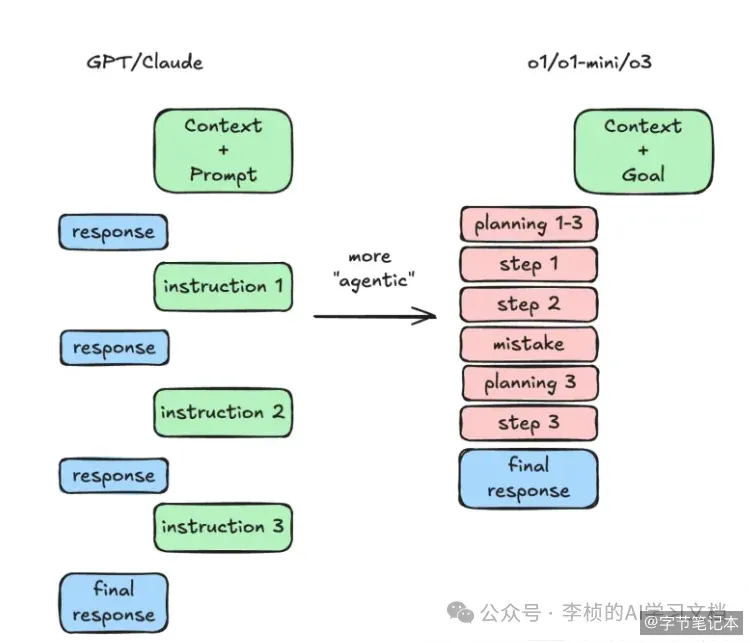
对于习惯了 GPT 结构化提示词的用户来说,切换到 DeepSeek R1 需要一次思维转换:从"教模型怎么回答"转变为"告诉模型你要什么"。前者是约束,后者是释放。而释放,才是推理模型真正擅长的事。
DeepSeek 的崛起标志着开源大模型的竞争进入了新阶段。DeepSeek V3 和 R1 系列模型在多个基准测试上的表现超越了同等规模的闭源模型,引发了行业对开源模型能力的重新评估。DeepSeek 的成功可以归结为几个关键因素。首先是训练效率的极致优化,通过 MoE 架构和创新的训练策略,在有限的算力预算下实现了突破性的性能。其次是推理成本的显著降低,DeepSeek 的 API 定价远低于主流闭源模型,让中小企业和个人开发者也能负担得起高质量的 AI 能力。DeepSeek 对开发者生态的重视也值得关注,通过开放模型权重和提供完善的文档,吸引了大量开发者在 DeepSeek 的基础上构建应用。对于开发者来说,关注 DeepSeek 的进展意味着获得了更多模型选择的自由,不再被单一供应商锁定。
AI 领域有一个普遍的趋势:技术进步的速度远超组织和个人的适应速度。这意味着今天的最佳实践可能在半年后就过时了。因此与其追求掌握某个特定技术的所有细节,不如培养快速学习和判断技术价值的能力。当一个新的框架或模型发布时,快速判断它对自己的工作有没有价值,值得花多少时间去学习。对于没有长期价值的热点,保持关注即可,不需要深入学习。对于有长期价值的趋势,投入足够的时间深入理解底层原理,而不仅仅是会使用工具。这种能力的培养需要持续阅读、实践和总结。每周花固定时间阅读技术博客和论文,每月做一个实践项目验证所学知识,每季度进行一次知识体系的复盘和重构。
在软件开发领域,有一条经验法则:任何在开发阶段看起来很聪明但让调试变得困难的做法,最终都不是好主意。这条法则在 AI 应用开发中尤其适用。AI 应用的不确定性比传统软件高得多,这意味着调试和排查问题的难度也大得多。因此 AI 应用的设计应该追求简单、透明、可追踪。简单意味着每个组件的职责清晰,组件之间的依赖关系明确。透明意味着系统的每个决策过程都可以被追溯和理解。可追踪意味着每次模型调用、每步推理过程都被记录在案。只有做到了这三条,你才能在系统出现问题时快速定位根因。
AI 项目的技术栈选择决定了开发效率和后期维护的成本。Python 是目前 AI 开发的主流语言,拥有最丰富的生态。TypeScript 在 AI 应用开发中也越来越流行,特别是在需要前后端一体化的场景中。选择技术栈时的核心原则是优先考虑团队熟悉的技术,减少学习成本。框架选择同理,LangChain 功能丰富但复杂度也高,直接调用 API 可能更可控。建议从最简单的方案开始,随着需求复杂度的增加逐步引入框架。过早的框架选择会让系统复杂度不必要地增加。